
서버리스 함수를 운영하다 보면 누구나 한 번쯤 이런 상황에 마주친다. 월초에 예상했던 비용의 두 배가 청구서에 찍혀 있고, 원인을 추적해보니 프로비저닝된 동시성 설정이 트래픽 패턴과 맞지 않았던 것이다. 콜드스타트를 줄이려고 동시성을 높였는데, 정작 트래픽이 몰리지 않는 시간대에도 비용이 빠져나가고 있었다.
이 글은 워크로드 패턴에 따라 콜드스타트와 동시성 프로비저닝을 어떻게 조합해야 비용을 최적화할 수 있는지를 실용 체크리스트 관점에서 정리한다. 끝까지 읽으면 자신의 서버리스 환경에 맞는 설정값을 직접 산출하고, 불필요한 과금을 차단하는 구체적 기준을 갖게 될 것이다.
프로비저닝 설정 전에 반드시 확인해야 할 것들
현재 워크로드 패턴 분류하기
설정을 건드리기 전에 먼저 자신의 워크로드가 어떤 유형인지 파악해야 한다. 크게 세 가지로 나뉜다. 간헐적 호출형(하루 수백~수천 건, 불규칙), 주기적 버스트형(특정 시간대에 트래픽 집중), 지속 트래픽형(분당 수백 건 이상 꾸준히 유입). 이 분류가 중요한 이유는 각 유형마다 콜드스타트의 영향도와 프로비저닝의 비용 효율이 완전히 다르기 때문이다.
실제 적용 사례를 살펴보면, 한 이커머스 스타트업에서 모든 Lambda 함수에 동일하게 프로비저닝 동시성 10을 설정했다가 월 비용이 40% 증가한 경우가 있다. 알림 발송 함수처럼 하루에 몇 번만 호출되는 함수에도 상시 프로비저닝을 걸어둔 것이 원인이었다.
측정 지표 수집 체크리스트
- 최근 30일간 시간대별 호출 수 분포 (CloudWatch Metrics 또는 Azure Monitor에서 확인)
- 평균 콜드스타트 지속 시간과 전체 호출 대비 콜드스타트 비율
- 동시 실행 최대치(ConcurrentExecutions)의 P95, P99 값
- 함수별 평균 실행 시간과 메모리 사용량 — 이 수치 없이 프로비저닝을 설정하면 감(感)에 의존하게 된다
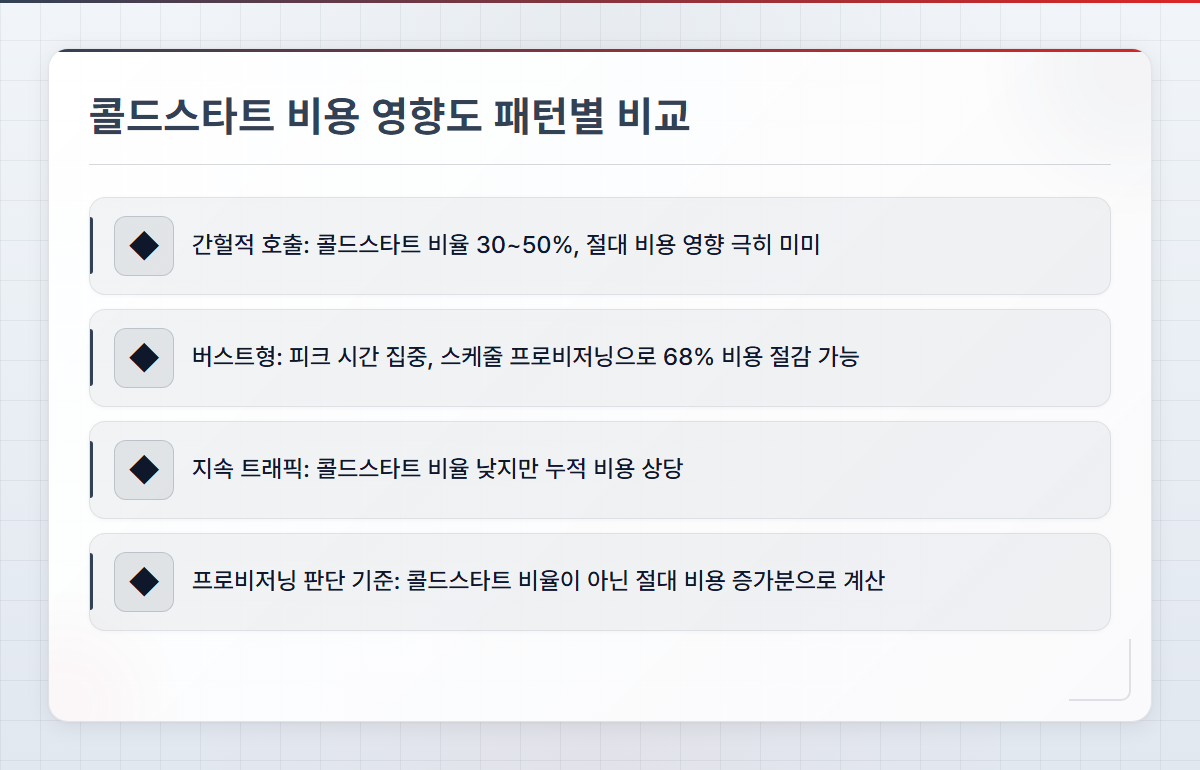
콜드스타트 비용 영향도, 어떤 패턴에서 얼마나 클까?
패턴별 콜드스타트 실질 비용 차이
콜드스타트 자체는 직접적인 추가 과금 항목이 아니다. 하지만 초기화 시간만큼 실행 시간이 늘어나므로 간접적으로 비용을 높인다. AWS Lambda 공식 문서에 따르면, 프로비저닝된 동시성을 사용하면 콜드스타트를 사실상 제거할 수 있지만 유휴 상태에서도 시간당 과금이 발생한다.
간헐적 호출형 워크로드에서는 콜드스타트가 전체 호출의 30~50%를 차지할 수 있다. 그런데 호출 자체가 적으니 절대 비용 증가분은 월 몇 달러에 불과하다. 반면 지속 트래픽형에서는 콜드스타트 비율이 1~3%로 낮지만, 호출 건수가 많아 누적 비용이 상당해진다. 여기서 핵심은 콜드스타트 비율이 아니라 콜드스타트로 인한 절대 비용 증가분을 계산해야 한다는 점이다.
구체적으로 따져보자. Lambda 함수가 메모리 512MB, 평균 실행 200ms, 콜드스타트 시 추가 800ms가 걸린다고 가정하면, 콜드스타트 1회당 추가 비용은 약 $0.0000067이다. 월 100만 건 호출에서 콜드스타트 비율 5%라면 추가 비용은 약 $0.33에 불과하다. 이 수준이라면 프로비저닝 비용이 오히려 더 클 수 있다.
서버리스 워크로드 패턴별 비용 최적화 전략: 프로비저닝 동시성 설정 단계
간헐적 호출형에는 프로비저닝이 독이 된다
하루 호출이 수백 건 이하인 함수에 프로비저닝 동시성을 설정하는 것은 빈 주차장에 월정액을 내는 것과 같다. 이 유형에서는 콜드스타트를 감수하되, 런타임 최적화로 초기화 시간을 줄이는 편이 합리적이다. Python이라면 함수 핸들러 바깥에서 import를 최소화하고, Java라면 GraalVM 네이티브 이미지나 SnapStart를 고려할 수 있다.
버스트형과 지속형에서의 설정 공식
주기적 버스트형이라면 트래픽 피크 시간대에만 프로비저닝을 활성화하는 스케줄 기반 오토스케일링이 핵심이다. AWS에서는 Application Auto Scaling의 예약된 작업으로 특정 시간대에만 프로비저닝 동시성을 높일 수 있다. 한 핀테크 기업에서는 평일 오전 9시~11시에만 동시성을 50으로 올리고 나머지 시간에는 5로 유지해서 프로비저닝 비용을 68% 절감한 사례가 있다.
지속 트래픽형에서는 다른 접근이 필요하다. 서버리스 컨테이너 전환 손익분기점을 먼저 계산해보는 것이 좋다. 프로비저닝 동시성 비용이 동일 워크로드를 Fargate나 Cloud Run으로 돌리는 비용을 초과한다면, 서버리스를 고집할 이유가 없다. 동시 실행 수의 P70 값을 프로비저닝 기준으로 잡고, 나머지 30%의 버스트는 온디맨드로 처리하는 것이 비용과 성능의 균형점이다.
설정 후 반드시 거쳐야 할 중간 점검 포인트
72시간 모니터링 체크리스트
프로비저닝 설정을 변경한 뒤 최소 72시간은 아래 지표를 관찰해야 한다.
- ProvisionedConcurrencyUtilization — 70% 미만이면 과잉 프로비저닝, 비용 낭비 구간
- ProvisionedConcurrencySpilloverInvocations — 이 값이 전체 호출의 20%를 넘으면 프로비저닝이 부족한 상태
- 비용 변화 추이 — AWS Cost Explorer에서 Lambda 항목을 프로비저닝/온디맨드로 분리 확인
많은 사람이 처음에는 프로비저닝을 설정하고 나서 확인을 소홀히 한다. 실제로 한 SaaS 기업에서 72시간 모니터링을 건너뛰었다가, 프로비저닝 활용률이 15%밖에 되지 않는 함수 3개를 한 달간 방치해 약 $420의 불필요한 비용이 발생했다.
플랫폼별 주의사항
Azure Functions Premium Plan에서는 ‘항상 준비된 인스턴스’ 수를 설정할 수 있지만, 최소 1개 인스턴스부터 과금되므로 소규모 워크로드에는 부담이 크다. Cloud Run은 최소 인스턴스를 0으로 설정할 수 있어 간헐적 호출에 유리하지만, CPU 할당 모드(요청 처리 중만 vs 항상)에 따라 비용 구조가 크게 달라진다. 모든 플랫폼에 동일한 전략을 적용할 수 없다는 점을 반드시 인식해야 한다.

비용 최적화 핵심 요약과 다음 단계 실행 계획
오늘 바로 적용할 수 있는 액션 아이템
가장 먼저 할 일은 현재 운영 중인 서버리스 함수 목록을 꺼내서 세 가지 패턴으로 분류하는 것이다. 간헐적, 버스트, 지속 — 이 분류만 해도 어디서 비용이 새고 있는지 절반은 보인다. 그 다음, 간헐적 호출 함수에 걸린 프로비저닝이 있다면 즉시 제거하고, 버스트형 함수에는 스케줄 기반 오토스케일링을 설정한다.
프로비저닝 동시성은 ‘보험’이 아니라 ‘투자’다. 투자 대비 수익(응답 시간 개선 대비 비용)이 맞지 않으면 과감히 해제해야 한다. 플랫폼별 과금 구조의 차이를 이해하고 있어야 이 판단이 가능하다.
한 가지 솔직하게 언급하자면, 이 전략이 모든 환경에 완벽히 맞지는 않는다. 규제 산업에서 응답 시간 SLA가 100ms 이하로 엄격한 경우, 비용보다 성능을 우선해야 하는 상황도 분명 존재한다. 비용 최적화는 언제나 성능 요구사항과의 트레이드오프 속에서 결정해야 한다.
정리하면 이렇다. 첫째, 워크로드 패턴을 분류하지 않은 채 프로비저닝을 설정하면 비용이 폭증한다. 둘째, 간헐적 호출에는 런타임 최적화, 버스트에는 스케줄 기반 동시성, 지속 트래픽에는 P70 기준 프로비저닝이 각각의 정답이다. 셋째, 설정 후 72시간 모니터링은 선택이 아니라 필수다. 오늘 당장 함수 목록을 열고 패턴 분류부터 시작해 보길 권한다.